6장 Resilience: Solving application networking challenges
- 주요 내용
- 회복탄력성의 중요성 이해 Understanding the importance of resilience
- 클라이언트 측 로드 밸런싱 활용 Leveraging client-side load balancing
- 요청 시간 초과 및 재시도 구현 Implementing request timeouts and retries
- 회로 차단 및 연결 풀링 Circuit breaking and connection pooling
- 마이그레이션 Migrating from application libraries used for resilience
- 회복 탄력성(Resilience) 필요한 이유
- 분산 시스템의 문제는 시스템이 이따금 예측할 수 없는 방식으로 실패하며 수작업으로 트래픽 전환 조치를 할 수 없다는 것이다.
- 따라서 문제가 발생했을 때 애플리케이션이 스스로 대응할 수 있도록 애플리케이션에 합리적인 동작을 구축할 수 있는 방법이 필요하다.
- 이스티오를 사용하면 애플리케이션 코드를 변경하지 않고도 타임아웃, 재시도, 서킷 브레이커를 추가할 수 있다.
1. Building resilience into the application
들어가며: 복원력 패턴 필요한 이유
- 마이크로서비스는 복원력을 최우선으로 고려해 구축해야 한다.
- ‘장애가 발생하지 않도록 구축하면 된다’고 말하는 세상은 현실이 아니다. 장애가 발생하면 모든 서비스를 중단시킬 위험이 있다.
- 네트워크로 통신하는 서비스로 분산 시스템을 구축할 때는 장애 지점을 더 많이 많들어낼 위험이 있으며, 치명적인 장애가 발생할 가능성을 마주하게 된다.
- 따라서 애플리케이션 및 서비스 전반에 걸쳐 몇 가지 복원력 패턴을 일관되게 채택해야 한다.
- 사례
- 서비스 A가 서비스 B를 호출했는데 서비스 B의 특정 엔드포인트로 전송이된 요청에서 지연이 발생했다면, 우리는 서비스 A가 이를 사전에 식별하고 다른 엔드포인트, 다른 가용 영역, 심지어 다른 리전으로 라우팅하길 원한다.
- 만약 서비스 B에 간간히 오류가 발생한다면 실패한 요청을 재시도할 수 있다.
- 마찬가지로 서비스 B를 호출하는 데 문제가 생긴다면, 그것이 무슨 문제든 서비스 B가 회복할 때까지 물러나야 할 수 있다.
- 계속 서비스 B로 부하를 가한다면(경우에 따라 요청을 재시도하면서 부하가 증폭되는 경우도 있음) 서비스를 과부하 상태로 만들 위험이 있다.
- 이런 과부하는 서비스 A와 이러한 서비스에 의존하는 모든 서비스에 파급돼 심각한 연쇄 오류를 일으킬 수 있다.
- 위에 사례 해결책은 애플리케이션이 장애를 예상해 요청을 처리할 때 자동으로 복원을 시도하거나 대체 경로로 돌아갈 수 있도록 구축하는 것이다.
- 서비스 A가 서비스 B를 호출할 때 문제가 발생한다면, 요청을 재시도하거나 타임아웃시키거나 서킷 브레이킹 패턴을 사용해 더 이상의 발신 요청을 취소할 수 있다.
- 애플리케이션의 프로그래밍 언어와 상관없이 애플리케이션에 복원력을 올바르고 일관되게 구현할 수 있도록, 이스티오를 사용해 이런 문제들을 투명하게 해결하는 방법 학습을 할것입니다.
1.1 Building resilience into application libraries : 언어 마다 구현 상이, 운영 부담
- 서비스 메시 기술이 등장 하기 전까지, 서비스 개발자들은 애플리케이션 코드에 복원력 패턴을 구현을 해야 했습니다.
- 이를 지원하기위해 오픈 소스 커뮤니티에서는 다양한 프레임워크가 등장 했습니다.
- 트위터 Finaglle - 공식 문서
- 2011년, 트위터는 자사의 복원력 프레임워크인 Finagle을 오픈소스화했습니다.
- Finagle은 스칼라/자바 기반 애플리케이션 라이브러리로, 타임아웃, 재시도, 서킷 브레이킹 등 다양한 RPC 복원력 패턴을 지원했습니다.
- 넷플릭스는 Hystrix(서킷 브레이커)와 Ribbon(클라이언트 측 로드 밸런싱) 같은 복원력 구성 요소를 오픈소스화했습니다.
- 위에 두 프레임워크는 자바 커뮤니티에서 큰 인기를 끌었고, 스프링 프레임워크에서는 Spring Cloud Netflix프로젝트를 통해 이를 통합하기도 했습니다.
- 프레임워크 기반 접근에는 한계
- 언어·프레임워크별 종속성 문제
- 트위터 Finagle이나 NetflixOSS 스택은 자바/JVM 기반 개발자에게는 효과적이었지만,
- Node.js, Go, Python 같은 다른 언어에서는 별도의 변형을 찾거나 직접 유사 기능을 구현해야 했습니다.
- 라이브러리가 애플리케이션 코드 침식
- 복원력 기능이 애플리케이션 로직에 깊숙이 침투하면서,비즈니스 로직과 네트워킹 코드가 뒤섞이고 관리가 어려워졌습니다.
- 운영·유지보수 부담 증가
- 다양한 언어와 프레임워크에 걸쳐 복원력 코드를 일관성 있게 유지해야 했습니다.
- 모든 조합을 동시에 패치하고 기능을 동일하게 유지하는 것은 큰 운영 부담으로 작용했습니다.
- 언어·프레임워크별 종속성 문제
1.2 Using Istio to solve these problems : 이스티오 서비스 프록시가 복원력 기능 제공

- Istio 서비스 프록시
- istio를 사용하면 서비스 프록시를 통해 애플리케이션 외부에서 복원력 기능을 구현할 수 있습니다.
- istio는 각 애플리케이션 인스턴스 옆에 서비스 프록시를 배치합니다.
- 애플리케이션이 주고받는 모든 네트워크 트래픽(HTTP 요청 등)을 가로채고 처리합니다.
- 애플리케이션 코드 수정 없이도 네트워크 통신 단에서 복원력 기능을 적용할 수 있습니다.
- 복원력 기능 적용 예시
- 서비스 간 통신 중 오류(예: HTTP 503)가 발생했을 때, Istio 프록시 레벨에서 자동으로 재시도를 수행할 수 있습니다.
- 재시도 동작은 재시도 실패 허용 횟수, 재시도 간 타임아웃, 총 재시도 시간 등 세밀한 설정이 가능합니다.
- 이 기능은 서비스 프록시가 Pod 단위로 배포되기 때문에, 애플리케이션마다 필요한 만큼 유연하게 제어할 수 있습니다.
- Istio가 기본으로 지원하는 복원력 패턴
- 클라이언트 측 로드 밸런싱 (Client-side load balancing)
- 지역 인식 로드 밸런싱 (Locality-aware load balancing)
- 타임아웃 및 재시도 (Timeouts and retries)
- 서킷 브레이킹 (Circuit breaking)
1.3 Decentralized implementation of resilience : 복원력 패턴을 분산 구현
- 중앙 집중형 구조의 한계
- 과거에는 로드 밸런서, 메시징 시스템, 엔터프라이즈 서비스 버스(ESB) 등 중앙 집중형 미들웨어를 요청 경로에 배치하여 복원력 기능을 제공했습니다.
- 유연성과 확장성에 한계가 있으며,클라우드 네이티브 아키텍처처럼 동적이고 분산된 환경에는 잘 맞지 않습니다.
- istio를 통한 분산 복원력
- istio를 사용하면 애플리케이션 코드에 라이브러리를 직접 삽입하거나 중앙 집중식 게이트웨이를 구축할 필요가 없습니다.
- istio는 애플리케이션 요청 경로에 Sidecar Proxy를 배치하여 애플리케이션 가까이에서 복원력 기능을 제공합니다.
- 네트워크 레벨에서 직접 재시도,타임아웃,서킷 브레이킹 등을 처리할 수 있어 애플리케이션 코드 수정 없이 복원력을 적용 할 수 있습니다.
- 실제 적용 예시
- simple-web 서비스가 여러 개의 simple-backend 서비스를 호출하는 구조
- 서비스 작동 방식을 좀 더 세밀하게 제어하기 위해 다른 샘플 애플리케이션 셋을 사용하는데, 이 프로젝트는 좀 더 현실적인 운영 환경에서 서비스가 어떻게 작동할 수 있는지 설명하기 위해 만든 닉 잭슨 Nic Jackson의 Fake Service 라는 프로젝트다.
- https://github.com/nicholasjackson/fake-service

2. Client-side load balancing 클라이언트 측 로드 밸런싱 (실습)
들어가며: EDS, DestinationRule(Client LoadBalancer)
- 클라이언트 로드 밸런싱(Client LoadBalancer) 쓰는 이유
- 엔드포인트 간에 요청을 최적으로 분산시키기 위해 클라이언트에게 서비스에서 사용할 수 있는 여러 엔드포인트를 알려주고 클라이언트가 특정 로드 밸런싱 알고리듬을 선택하게 하는 방식을 말한다.
- 병목 현상과 장애 지점을 만들 수 있는 중앙집중식 로드 밸런싱에 의존할 필요성이 줄어들고, 클라이언트가 군더더기 홉을 거칠 필요 없이 특정 엔드포인트로 직접적이면서 의도적으로 요청을 보낼 수 있다.
- 클라이언트와 서비스는 더 잘 확장돼 변화하는 토폴로지에 대응할 수 있다
- istio에서 동작 설명
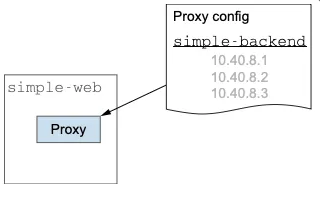
- 이스티오는 서비스 및 엔드포인트 디스커버리를 사용해 서비스 간 통신의 클라이언트 측 프록시에 올바른 최신 정보를 제공합니다.
- 서비스 운영자와 개발자는 DestinationRule 리소스로 클라이언트가 어떤 로드 밸런싱 알고리즘을 사용할지 설정할 수 있습니다.
- 이스티오 서비스 프록시는 엔보이 기반이며 엔보이의 지원하는 로드 밸런싱 알고리즘은 다음과 같습니다.
- 라운드 로빈(기본값)
- 랜덤
- 가중치를 적용한 최소 요청
- Server side load balancing vs. Client side load balancing
- Servier side LB: 클라이언트 요청이 먼저 로드 밸런서 서버로 전달 되고, 로드 밸런서가 적절한 서버 인스턴스를 선택해 트래픽을 분산하는 방식.
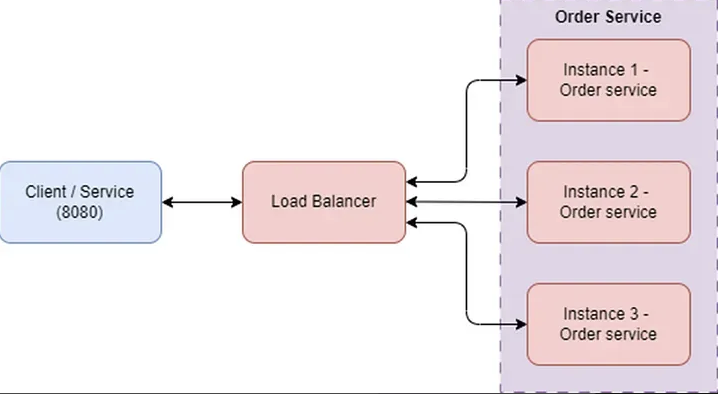
- Client side LB: 클라이언트가 자체적으로 여러 서버 인스턴스를 알고 있으며 요청시 클라이언트가 직접 인스턴스를 선택해 트래픽을 분산하는 방식

- 비교: 장단점
| 항목 | Server side LB | Client side LB |
| 장점 | - 클라이언트가 서버 목이나 부하 상태를 몰라도 됨 - 중앙 집중 제어 및 트래픽 최적화 가능 - 클라이언트 코드가 간단함 |
- 로드 밸런서 서버 없이 동작 가능(네트워크 홉감소) - 더 빠른 장애 감지 및 대응 가능 - 각 클라이언트가 독립적인 부하 분산 전략을 최적화 할수 있음. |
| 단점 | - 로드 밸런서 서버가 장애나 병목 지점이 될수 있음 - 관리와 확장이 필요함. - 추가 네트워크 홉 발생. |
- 클라이언트가 서버 리스트와 부하 상태를 주기적으로 동기화해야 함 - 클라이언트 코드 복잡도 증가 - 모든 클라이언트에 일관된 상태를 유지하는 것이 어려움 |
2.1 Getting started with client-side load balancing : DestinationRule 실습
- 실습 전 초기화
kubectl delete gw,vs,deploy,svc,destinationrule --all -n istioinaction- simple-backend.yaml 파일 수정 - kiali 버전 확인을 위해
# kiali 에서 simple-backend-1,2 버전 확인을 위해서 labels 설정
# ch6/simple-backend.yaml 파일을 수정합니다.
...
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-backend
version: v1 # 해당 코드 추가
name: simple-backend-1
spec:
replicas: 1
selector:
matchLabels:
app: simple-backend
template:
metadata:
labels:
app: simple-backend
version: v1 # 해당 코드 추가
...
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-backend
version: v2 # 해당 코드 추가
name: simple-backend-2
spec:
replicas: 2
selector:
matchLabels:
app: simple-backend
template:
metadata:
labels:
app: simple-backend
version: v2 # 해당 코드 추가
...
- 에제 서비스 2개 배포 및 확인
# 예제 서비스 2개 배포
kubectl apply -f ch6/simple-backend.yaml -n istioinaction
kubectl apply -f ch6/simple-web.yaml -n istioinaction
# 확인
kubectl get deploy,pod,svc,ep -n istioinaction -o wide

- gw ,vs 배포 및 확인
# simple-web-gateway.yaml 코드
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: simple-web-gateway
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "simple-web.istioinaction.io"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: simple-web-vs-for-gateway
spec:
hosts:
- "simple-web.istioinaction.io"
gateways:
- simple-web-gateway
http:
- route:
- destination:
host: simple-web
# 생성
kubectl apply -f ch6/simple-web-gateway.yaml -n istioinaction
# 확인
kubectl get gw,vs -n istioinaction
docker exec -it myk8s-control-plane istioctl proxy-status
# 도메인 질의를 위한 임시 설정 : 실습 완료 후에는 삭제 해둘 것
echo "127.0.0.1 simple-web.istioinaction.io" | sudo tee -a /etc/hosts

- 테스트 kiali로 확인
# 신규 터미널 : 반복 접속 실행 해두기
while true; do curl -s http://simple-web.istioinaction.io:30000 | jq ".upstream_calls[0].body" ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done

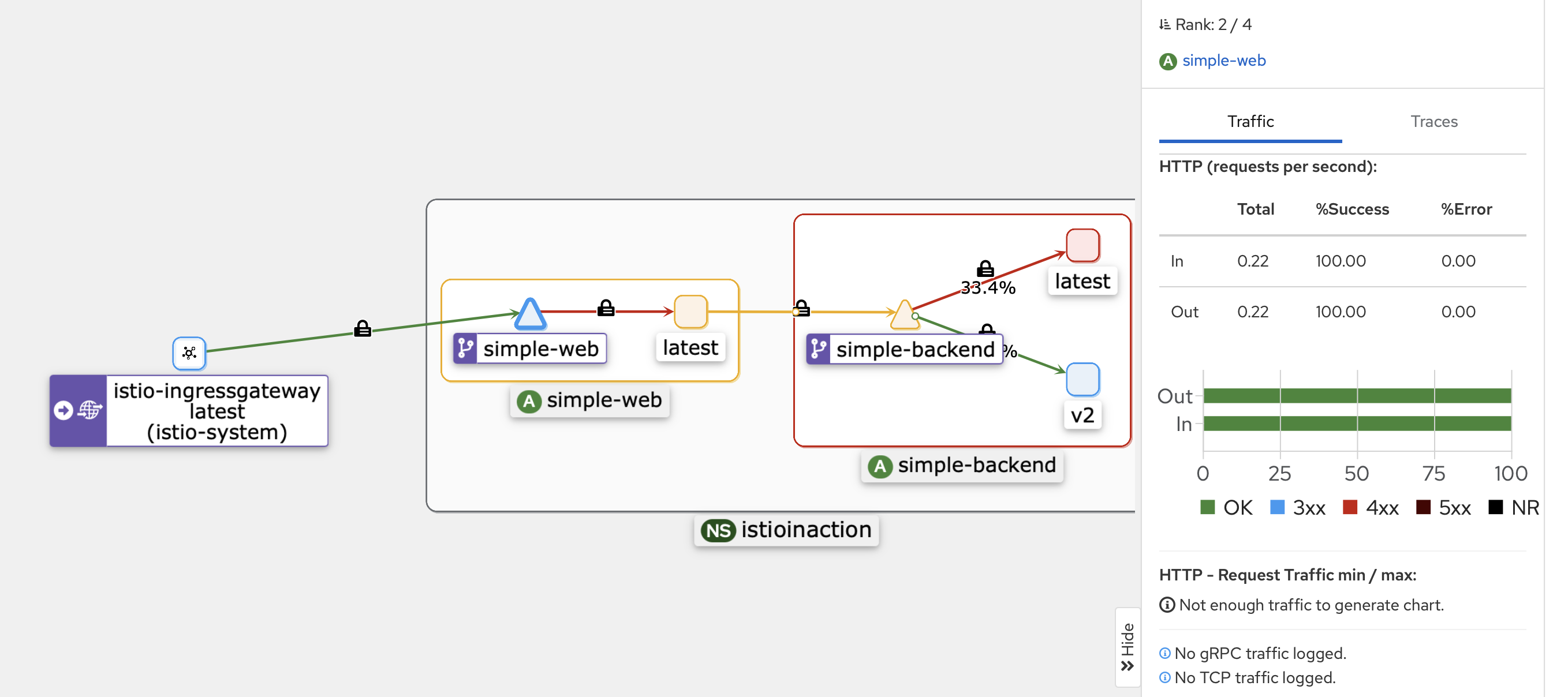
- DestinationRule는 특정 목적지를 호출하는 메시 내 클라이언트들에 정책을 지정한다.
- 이스티오 DestinationRule 리소스로 simple-backend 서버스를 호출하는 모든 클라이언트의 로드 밸런싱을 라운드 로빈으로 설정 해보자
- 라운드 로빈 적용
- simple-web 과 simple-backend 간 호출이 여러 simple-backend 엔드포인트로 효과적으로 분산되는 것을 확인할 수 있다.
- simple-web 과 simple-backend 간의 클라이언트 측 로드 밸런싱을 보고 있는데, simple-web 과 함께 배포된 서비스 프록시가 모든 simple-backend 엔드포인트를 알고 있고 기본 알고리즘을 사용해 요청을 받을 엔드포인트를 결정하고 있기 때문이다.
- ROUND_ROBIN 로드 밸런싱을 사용하도록 DestinationRule 을 설정
- kiali 에서 비슷하게 동작하는것을 확인 할수 있다.
- 이스티오 서비스 프록시의 기본 설정도 ROUND_ROBIN 로드 밸런싱 전략을 사용한다
# simple-backend-dr-rr.yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN # 엔드포인트 결정을 '순서대로 돌아가며'
kubectl apply -f ch6/simple-backend-dr-rr.yaml -n istioinaction
# 확인 : DestinationRule 단축어 dr 이다
kubectl get dr -n istioinaction


2.2 Setting up our scenario : Fortio 설치
- 현실적인 환경에서 서비스가 요청을 처리하는 데 시간이 걸린다. 소요 시간은 여러 이유로 달라질 수 있다.
- 요청 크기 Request size
- 처리 복잡도 Processing complexity
- 데이터베이스 사용량 Database usage
- 시간이 걸리는 다른 서비스 호출 Calling other services that take time
- 서비스 외적인 이유도 응답 시간에 영향을 줄 수 있다.
- 예기치 못한, 모든 작업을 멈추는 stop-the-world 가비지 컬렉션 Unexpected, stop-the-world garbage collections
- 리소스 경합 Resource contention (CPU, 네트워크 등)
- 네트워크 혼잡 Network congestion
- Fortio 도구 쓰는 이유
- 서비스를 호출 할 때마다 응답 시간이 달라진다.
- 로드 밸런싱은 주기적으로 혹은 예기치 못하게 지연 시간이 급증하는 엔드포인트의 영향을 줄이는 효과적인 전략이 될 수 있다.
- Fortio는 CLI 부하 생성 도구를 사용해 서비스를 실행하고 클라이언트 측 로드 밸런싱의 차이를 관찰 할 수 있다.
- Fortio 설치
# mac forito 설치
brew install fortio
fortio -h
fortio server
# forito로 우리 서비스 호출 테스트
fortio curl http://simple-web.istioinaction.io:30000

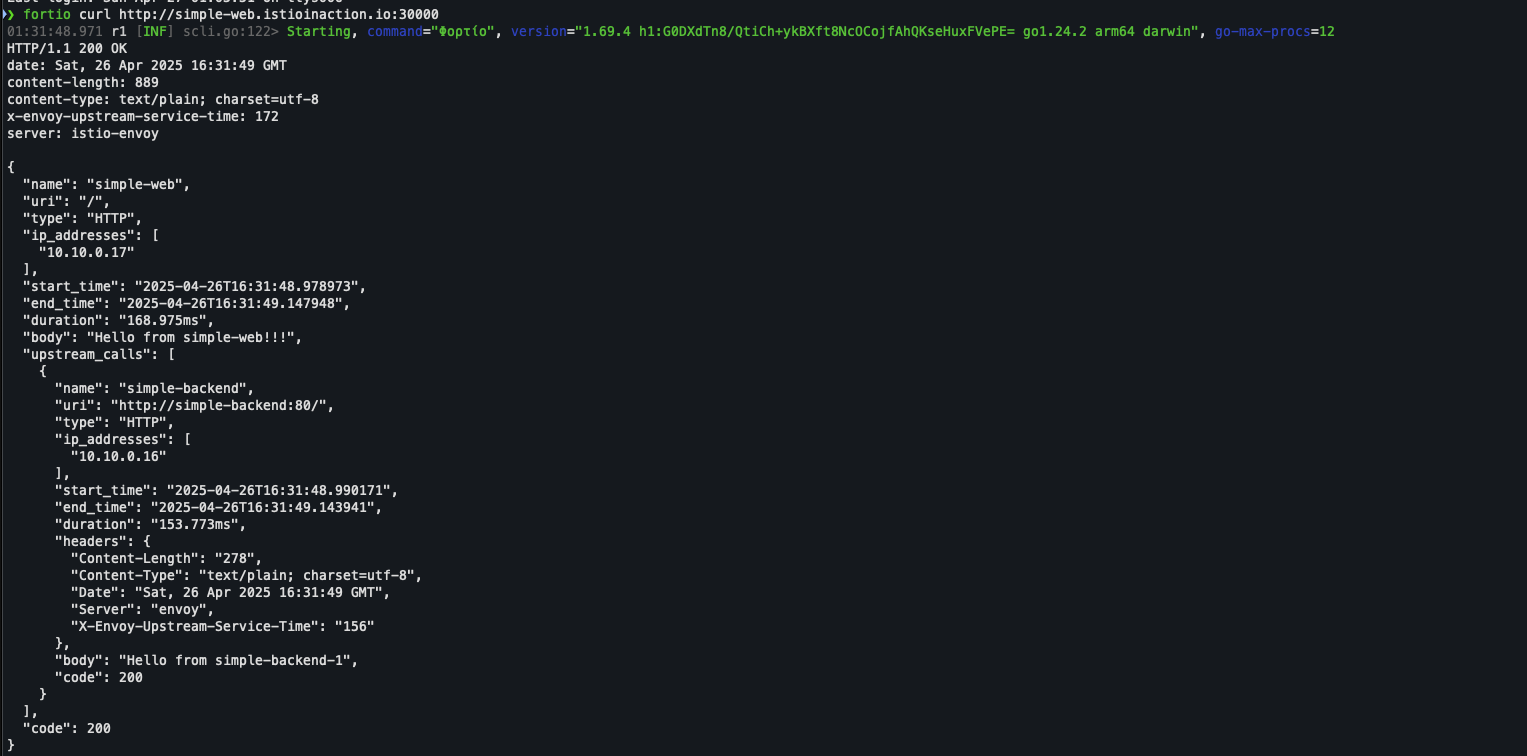
2.3 Testing various client-side load-balancing strategies* : LB 알고리즘에 따란 지연 시간 성능 측정
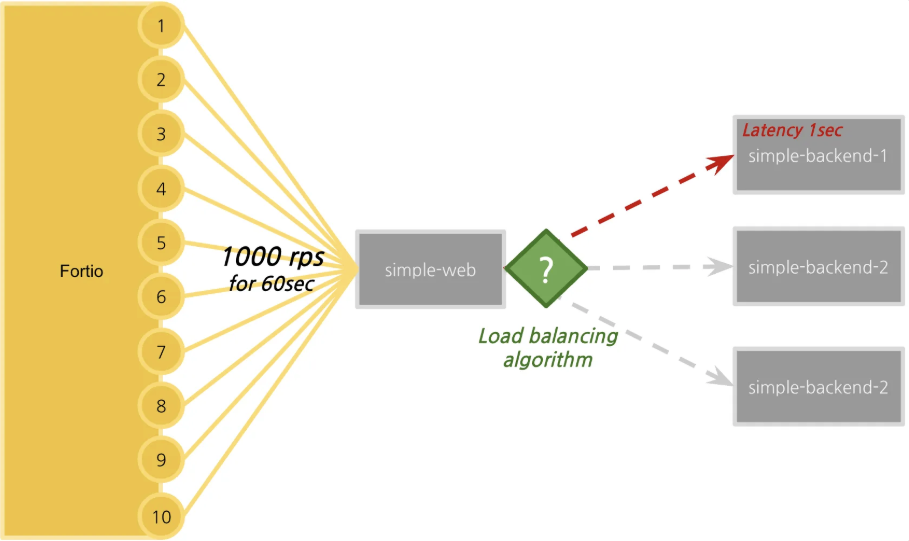
- Fortio를 이용한 테스트 환경을 다음과 같이 구성을 합니다.
- Fortio를 사용해서 60초 동안 10개의 커넥션을 통해 초당 1000개의 요청을 보낸다.
- Fortio는 각 호출의 지연 시간을 추적하고 지연 시간 백분위수 분석과 함께 히스토그램에 표시한다.
- 테스트를 하기 전에 지연 시간을 1초까지 늘린 simple-backend-1 서비스를 도입할 것이다.
- 엔드포인트 중 하나에 긴 가비지 컬렉션 이벤트 또는 기타 애플리케이션 지연 시간이 발생한 상황을 시뮬레이션한다.
- 로드 밸런싱 전략을 라운드 로빈, 랜덤, 최소 커넥션으로 바꿔가면서 차이점을 관찰할 것이다.
- 지연된 simple-backend-1 서비스를 배포
# simple-backend-delayed.yaml 내용
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-backend
name: simple-backend-1
spec:
replicas: 1
selector:
matchLabels:
app: simple-backend
template:
metadata:
labels:
app: simple-backend
spec:
serviceAccountName: simple-backend
containers:
- env:
- name: "LISTEN_ADDR"
value: "0.0.0.0:8080"
- name: "SERVER_TYPE"
value: "http"
- name: "NAME"
value: "simple-backend"
- name: "MESSAGE"
value: "Hello from simple-backend-1"
- name: "TIMING_VARIANCE"
value: "10ms"
- name: "TIMING_50_PERCENTILE"
value: "1000ms"
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
image: nicholasjackson/fake-service:v0.17.0
imagePullPolicy: IfNotPresent
name: simple-backend
ports:
- containerPort: 8080
name: http
protocol: TCP
securityContext:
privileged: false
kubectl apply -f ch6/simple-backend-delayed.yaml -n istioinaction
kubectl rollout restart deployment -n istioinaction simple-backend-1
- Fortio로 테스트 - 라운드로빈
- Title : roundrobin
- URL : http://simple-web.istioinaction.io:30000
- QPS : 1000
- Duration : 60s
- Threads : 10
- Jitter: Check
- No Catch-up : Uncheck
- Extra Headers
- User-Agent: fortio
- Timeout : 2000m
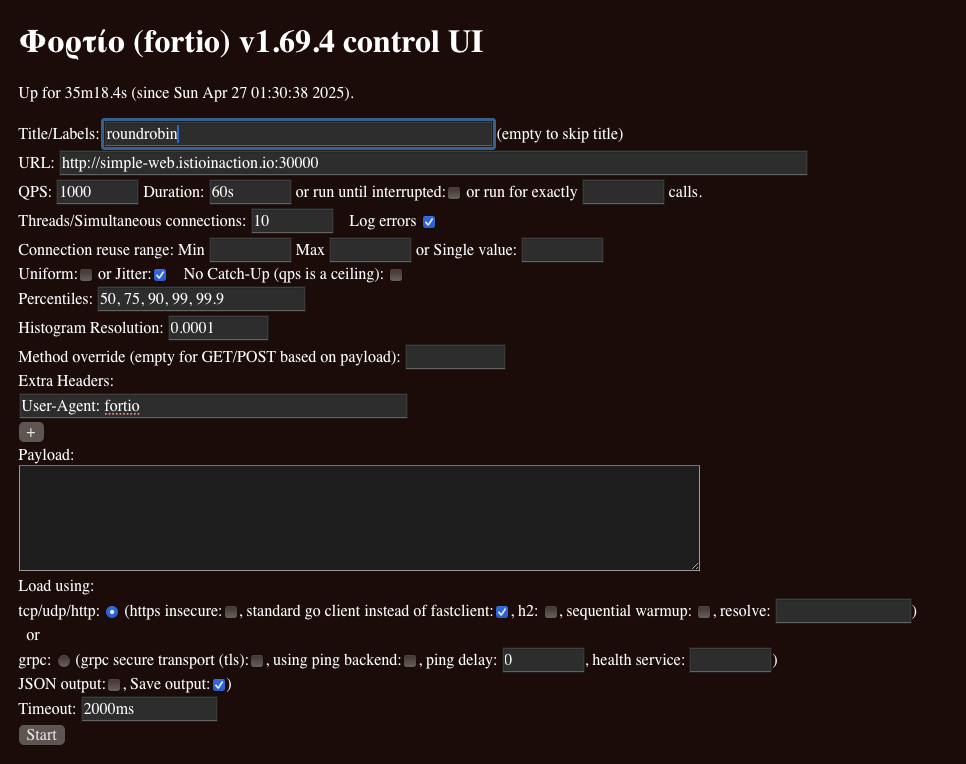

- 이 라운드 로빈 밸런싱 전략의 경우 지연 시간 결과 ⇒ 75분위수에서 응답이 1초 이상 걸림.

- Fortio로 테스트 - 랜덤
# simple-backend-dr-random.yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer:
simple: RANDOM
# 적용
kubectl apply -f ch6/simple-backend-dr-random.yaml -n istioinaction
- Fortio 설정
- Title : random
- URL : http://simple-web.istioinaction.io:30000
- QPS : 1000
- Duration : 60s
- Threads : 10
- Jitter: Check
- No Catch-up : Uncheck
- Extra Headers
- User-Agent: fortio
- Timeout : 2000ms
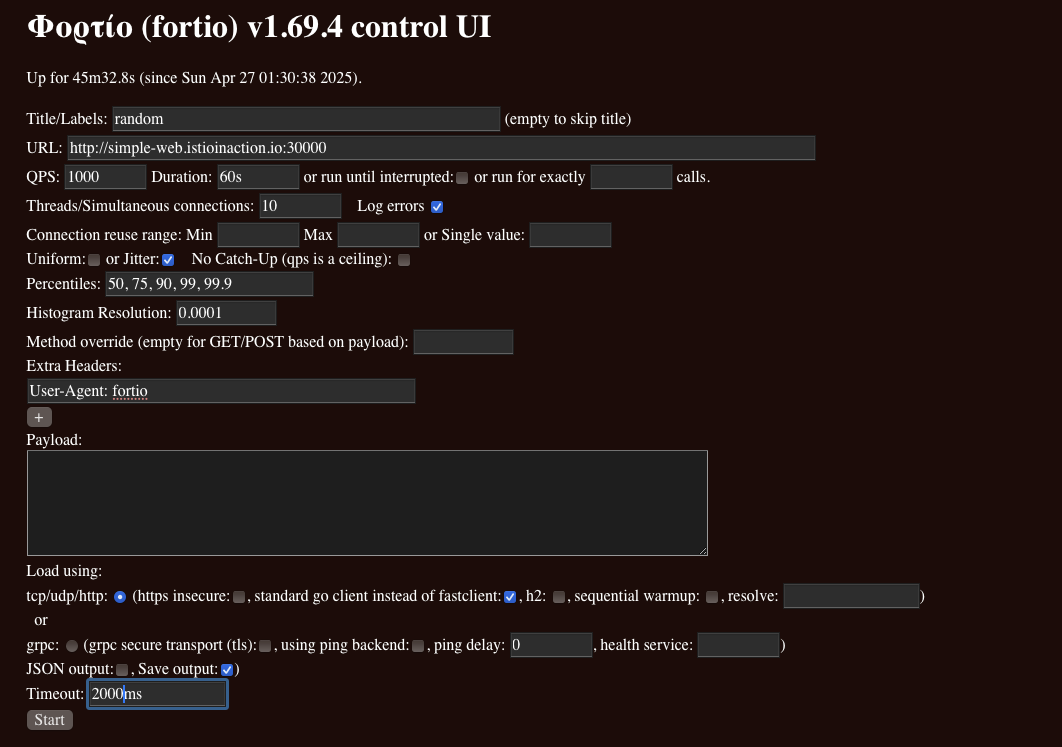

- RANDOM 로드 밸런싱 알고리듬 지연 시간 결과 ⇒ ⇒ 75분위수에서 응답이 1초 이상 으로 RoundRobin 과 비슷함

- Forito 테스트 - Least connection
# simple-backend-dr-least-conn.yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer:
simple: LEAST_CONN
# 적용
kubectl apply -f ch6/simple-backend-dr-least-conn.yaml -n istioinaction
- Fortio 설정
- Title : least_conn
- URL : http://simple-web.istioinaction.io:30000
- QPS : 1000
- Duration : 60s
- Threads : 10
- Jitter: Check
- No Catch-up : Uncheck
- Extra Headers
- User-Agent: fortio
- Timeout : 2000ms
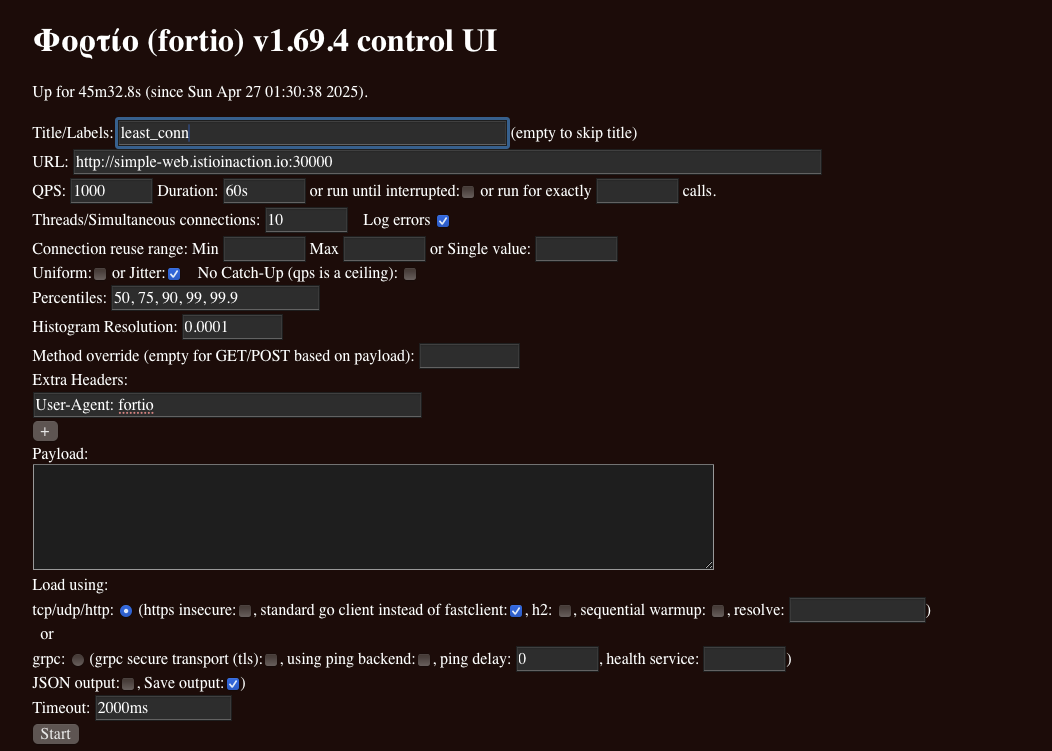

- Least connection로드 밸런싱 알고리듬 지연 시간 결과 ⇒ 75분위수에서 응답이 200ms(0.19..) 이내 응답성능으로, RR, Random 보다 좋음!

2.4 Understanding the different load-balancing algorithms
- 로드 테스트 결과 요약
- 여러 로드 밸런서는 현실적인 서비스 지연 시간 동작하에서 만들어내는 결과가 서로 다르다.
- 히스토그램과 백분위수는 모두 다르다.
- 최소 커넥션(Least connection)이 랜덤과 라운드 로빈보다 성능이 좋다
- 라운드 로빈
- 순차적으로 요청을 엔드포인트에 분배합니다. 구현이 쉽고 쉽고 균등 분배를 기대할 수 있지만,
- 엔드포인트 별 부하 상태를 고려하지 않기 때문에 부하 불균형이 생길 수 있습니다.
- 랜덤
- 무작위로 엔드포인트를 선택해 요청을 분배합니다. 매우 간단하지만, 엔드포인트 상태를 고려하지 않기 때문에 비효율이 발생할 수 있습니다.
- 라운드 로빈 과 랜덤 방식은 모두 엔드포인트의 현재 부하나 지연 시간을 고려하지 않고 분배합니다.
- 최소 커넥션 (Least Connection)
- 활성 연결이 가장 적은 엔드포인트를 선택해 트래픽을 분산합니다.
- 긴 지연 시간이나 처리 속도 차이가 큰 엔드포인트들이 있을 때 효과적입니다.
- 커넥션 수가 아니라 요청 수(queue depth) 를 기준으로 가장 활성 요청이 적은 엔드포인트를 선택합니다.
- “두 개의 후보를 무작위로 뽑고 비교하여 더 적은 쪽을 선택하는 방식”을 사용합니다. 이를 “두 가지 선택의 힘 (Power of Two Choices)” 이라고 부릅니다.
- 왜 최소 커넥션 방식이 효과적인가?
- 전체 엔드포인트를 모두 스캔하지 않고도 빠르게 적절한 엔드포인트를 선택할 수 있습니다.
- 로드 테스트 결과, 랜덤이나 라운드로빈보다 훨씬 안정적이고 일관된 지연 시간을 보여줍니다.
- 특히 지연 시간이 고르지 않은 환경(불균형 트래픽 상황)에서는 큰 차이를 만듭니다
- 요약: 비교
| 항목 | 특징 | 장단점 |
| 라운드 로빈(Round Robin) | 순서대로 분배 | 간단하지만 부하 상태 반영 불가 |
| 랜덤(Random) | 무작위로 분배 | 간단하지만 부하 불균형 위험 |
| 최소 커넥션(Least Connection) | 활성 요청 수가 적은 엔드 포인트 선택 | 부하를 고려한 스마트한 분배,복잡도 증가 |
3. Locality-aware load balancing 지역 인식 로드 밸런싱 (실습)
들어가며: 배경 소개
- 이스티오 같은 컨트롤 플레인의 역할 중 하나는 서비스 토폴로지를 이해하고 그 토폴로지가 어떻게 발전할 수 있는지 파악하는 것이다.
- 서비스 메시에서 전체 서비스 토폴로지를 이해할 때의 이점은 서비스와 피어 서비스의 위치 같은 휴리스틱 heuristic 을 바탕으로 라우팅과 로드 밸런싱을 자동으로 결정할 수 있다는 점이다.

- 이스티오가 지원하는 로드 밸런싱 유형에는 워크로드의 위치에 따라 루트에 가중치를 부여하고 라우팅 결정을 내리는 것이다.
- 예를 들어 이스티오는 특정 서비스를 배포한 리전과 가용 영역을 식별하고, 더 가까운 서비스에 우선순위를 부여할 수 있다.
- 만약 simple-backend 서비스를 여러 리전에 배포했다면(us-west, us-east, europe-west), 호출하는 방법은 여러 가지가 있다.
- simple-web을 us-west 리전에 배포했다면, 우리는 simple-web이 하는 simple-backend 호출이 us-west 로컬이길 바랄 것이다.
- 모든 엔드포인트를 동등하게 취급한다면 리전이나 영역을 넘나들면서 지연 시간이 길어지고 비용이 발생할 가능성이 크다.
3.1 Hands-on with locality load balancing
- 지역 인식 로드 밸런싱
- 쿠버네티스에 배포할 때, 리전과 영역 정보를 노드 레이블에 추가할 수 있다.
- 예를 들어 failure-domain.beta.kubernetes.io/region 레이블 및 failure-domain.beta.kubernetes.io/zone 은 각각 리전과 영역을 지정 할 수 있게 해준다.
- 최근에는 쿠버네티스 API 정식 버전에서는 이 레이블들을 topology.kubernetes.io/region 과 topology.kubernetes.io/zone 으로 대체했다.
- 이런 레이블은 구글 클라우드나 AWS 같은 클라우드 프로바이더가 자동으로 추가하는 경우가 많다.
- 이스티오는 이런 노드 레이블을 가져와 엔보이 로드 밸런싱 엔드포인트에 지역 정보로 보강한다.
- 이스티오에는 워크로드에 지역을 명시적으로 설정할 수 있는 방법이 있다.
- 파드에 istio-locality 라는 레이블을 달아 리전/영역을 지정할 수 있다.
- 이러면 지역 인식 라우팅 및 로드 밸런싱을 시연하기에 충분하다.
- 지역 인식 로드 밸런싱 적용한 simple-web 디플로이먼트 분석
- simple-backend 서비스를 배포할 때 지역 레이블을 다양하게 지정할 것이다.
- simple-web과 같은 지역인 us-west1-a 에 simple-backend-1을 배포한다.
- 그리고 us-west1-b 에 simple-backend-2 를 배포한다. 이 경우, 리전은 동일하지만 영역이 다르다.
- 지역 간에 로드 밸런싱을 수행할 수 있는 이스티오의 기능에는 리전, 영역, 심지어는 더 세밀한 하위 영역 subzone 도 포함된다.
# simple-service-locality.yaml
# 이전 처럼 kiali 라벨 분기를 위해 코드 수정
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-web
name: simple-web
spec:
replicas: 1
selector:
matchLabels:
app: simple-web
template:
metadata:
labels:
app: simple-web
istio-locality: us-west1.us-west1-a
...
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-backend
name: simple-backend-1
spec:
replicas: 1
selector:
matchLabels:
app: simple-backend
template:
metadata:
labels:
app: simple-backend
istio-locality: us-west1.us-west1-a
version: v1 # 추가해두자!
...
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-backend
name: simple-backend-2
spec:
replicas: 2
selector:
matchLabels:
app: simple-backend
template:
metadata:
labels:
app: simple-backend
istio-locality: us-west1.us-west1-b
version: v2 # 추가해두자!
...
- 서비스 배포 확인
# 배포
kubectl apply -f ch6/simple-service-locality.yaml -n istioinaction
# 확인
## simple-backend-1 : us-west1-a
kubectl get deployment.apps/simple-backend-1 -n istioinaction \
-o jsonpath='{.spec.template.metadata.labels.istio-locality}{"\n"}'
## simple-backend-2 : us-west1-b
kubectl get deployment.apps/simple-backend-2 -n istioinaction \
-o jsonpath='{.spec.template.metadata.labels.istio-locality}{"\n"}'

- 이스티오의 지역 인식 로드 밸런싱은 기본적으로 활성화돼 있다. https://istio.io/v1.17/docs/reference/config/istio.mesh.v1alpha1/
- 비활성화 하고 싶다면, meshConfig.localityLbSetting.enabled: false 로 설정하면 된다.
- 이스티오의 지역 인식 로드 밸런싱 사용해야 하는 이유 - https://karlstoney.com/locality-aware-routing/
- 앞서 시뮬레이션한 것치럼, 클러스터의 노드가 여러 가용성 영역에 배포돼 있다면 기본 지역 인식 로드 밸런싱이 항상 바람직하지는 않을 수도 있음을 고려해야 한다.
- 우리 예제에서는 어느 지역에서도 simple-backend(목표 서비스) 복제본이 simple-web(호출하는 서비스)보다 적지 않다.
- 그러나 실제 환경에서는 특정 지역에서 호출하는 서비스 인스턴스 보다 목표 서비스 인스턴스가 적게 배포될 수도 있다.
- 이런 경우 목표 서비스가 과부하를 겪을 수 있고, 시스템 전체의 부하가 의도한 것처럼 불균형하게 분산될 수 있다.
- 결국 부하 특성과 토폴로지에 맞춰 로드 밸런싱을 튜닝하는 것이 중요하다.
- 지역 정보가 준비되면, us-west1-a 에 있는 simple-web 호출이 같은 영역인 us-west1-a 에 배포된 simple-backend 서비스로 갈 것으로 기대할 수 있다.
- 우린 예제에서는 simple-web의 모든 트래픽이 us-west1-a 에 있는 simple-backend-1 로 향한다.
- simple-backend-2 서비스는 simple-web 과 다른 영역인 us-west-1b에 배포돼 있으므로, us-west1-a 에 있는 서비스가 실패하기 시작할 때만 simple-backend-2 로 향할 것으로 기대할 수 있다.
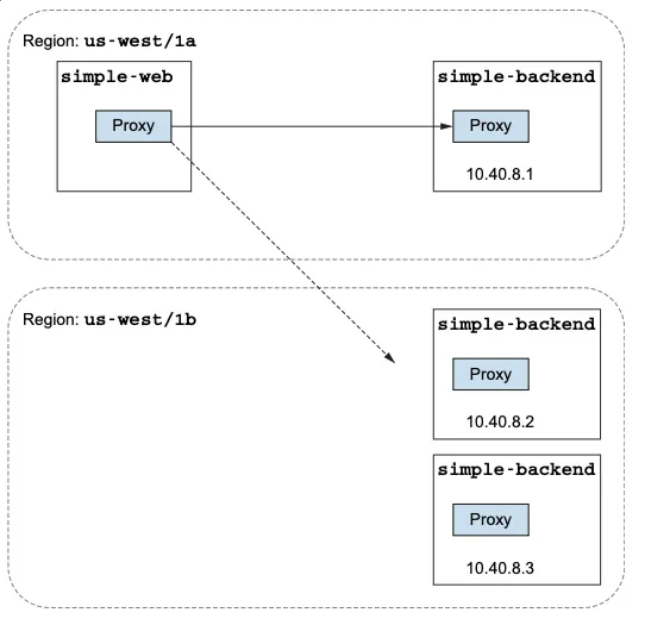
- 호출 테스트 1 ⇒ 지역 정보를 고려하지 않고 simple-backend 모든 엔드포인트로 트래픽이 로드 밸런싱 됨
- 이스티오에서 지역 인식 로드밸런싱이 작동하려면 헬스 체크를 설정해야 한다.
- 헬스 체크가 없으면 이스티오가 로드 밸런싱 풀의 어느 엔드포인트가 비정상 인지, 다음 지역으로 넘기는 판단 기준은 무엇인지를 알 수 없다.
- 이상값 감지는 엔드포인트의 동작과, 엔드포인트가 정상적으로 보이는지 여부를 수동적으로 감시한다.
- 엔드포인트가 오류를 반환하는지 지켜보다가, 오류가 반환되면 엔드포인트를 비정상으로 표시한다.
- simple-backend 서비스에 이상값 감지를 설정해 수동적인 헬스 체크 설정을 추가
# simple-backend-dr-outlier.yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
outlierDetection:
consecutive5xxErrors: 1
interval: 5s
baseEjectionTime: 30s
maxEjectionPercent: 100
# 적용
kubectl apply -f ch6/simple-backend-dr-outlier.yaml -n istioinaction
# 확인
kubectl get dr -n istioinaction simple-backend-dr -o jsonpath='{.spec}' | jq

- 호출 테스트 -Kiali로 확인
- 모든 트래픽이 simple-web과 동일한 영역에 있는 simple-backend-1 서비스로 가고 있다.
while true; do curl -s http://simple-web.istioinaction.io:30000 | jq ".upstream_calls[0].body" ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
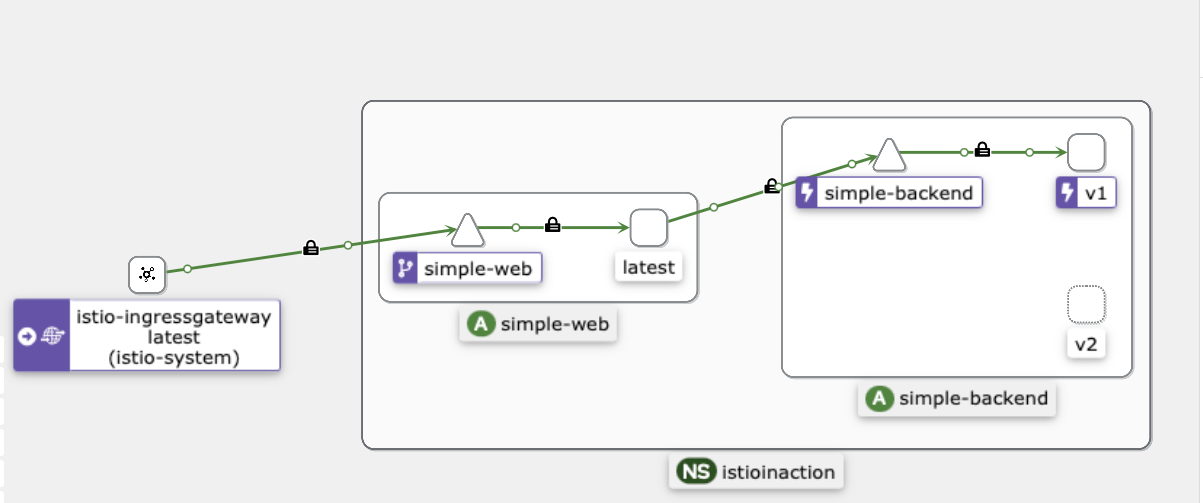
- 호출 테스트 2 : 오동작 주입 후 확인
- 트래픽이 가용 영역을 넘어가는 것을 보기 위해 simple-backend-1 서비스를 오동작 상태로 만들어보자.
- simple-web 에서 simple-backend-1 호출하면 항상 HTTP 500 오류를 발생하게 하자
- 이렇게 특정 지역의 서비스가 제대로 동작하지 않을 때 예상하는 지역 인식 로드 밸런싱 결과를 얻을 수 있다.
- 이 지역 인식 로드 밸런싱은 단일 클러스터 내부에서 이뤄지는 것임을 유의하자
# HTTP 500 에러를 일정비율로 발생 simple-service-locality-failure.yaml
...
- name: "ERROR_TYPE"
value: "http_error"
- name: "ERROR_RATE"
value: "1"
- name: "ERROR_CODE"
value: "500"
...
# 배포
kubectl apply -f ch6/simple-service-locality-failure.yaml -n istioinaction
# 확인
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/simple-web.istioinaction --cluster 'outbound|80||simple-backend.istioinaction.svc.cluster.local'


- 다음 실습을 위해 simple-backend-1 을 정상화
kubectl apply -f ch6/simple-service-locality.yaml -n istioinaction
3.2 More control over locality load balancing with weighted distribution : 가중치 분포로 지역 인식 LB 제어 강화
- 지역 가중 분포 (locality weighted distribution
- 이스티오의 기본 설정에서 서비스 프록시는 모든 트래픽을 동일 지역의 서비스로 보내고, 장애나 비정상 엔드포인트가 있을 때만 다른 지역으로 넘긴다.
- 하지만 트래픽 일부를 여러 지역에 분산하고 싶다면 이 동작에 영향을 줄 수 있는데, 이를 지역 가중 분포 locality weighted distribution 라고 한다.
- 특정 지역의 서비스가 피크 peak 시간이나 계절성 트래픽으로 인해 과부하될 것으로 예상될 경우 이런 방법을 사용할 수 있다.
- 특정 영역에서 리전이 처리 할 수 없는 부하가 들어온다고 가정
- 트래픽의 70%가 최인접 지역으로 가고, 30%가 인접 지역으로 가길 원한다.
- 앞선 예제를 따라 simple-backend 서비스로 가는 트래픽 70%를 us-west1-a로, 30%를 us-west1-b로 보낼 것이다.

- LB에 가중치 적용
- 일부 요청이 분산됐다. 대부분은 가장 가까운 지역으로 향했지만, 일부 요청은 다음 인접 지역으로 넘어가는 경우도 있었습니다.
- 트래픽 라우팅에서는 서비스의 부분집합 간에 트래픽 비중을 제어할 수 있었고, 보통 전체 서비스 그룹 내에서 종류나 버전이 여럿일 때 사용한다.
- 위 예제에서는 서비스의 배포 토폴로지를 바탕으로 트래픽에 가중치를 부여했고, 부분집합과는 무관한다.
- 부분집합 라우팅(subset routing)과 가중치 부여는 상호 배타적인 개념이 아니다.
- 이 둘은 중첩될 수 있으며, 세밀한 트래픽 제어 및 라우팅을 이번 절에서 살펴본 지역 인식 로드 밸런서 위에 적용 할 수 있다.
- 부분 집합 라우팅 ,과 가중치 부여 함께 중첩 해서 사용 할수 있다는 의미
# simple-backend-dr-outlier-locality.yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer: # 로드 밸런서 설정 추가
localityLbSetting:
distribute:
- from: us-west1/us-west1-a/* # 출발지 영역
to:
"us-west1/us-west1-a/*": 70 # 목적지 영역
"us-west1/us-west1-b/*": 30 # 목적지 영역
connectionPool:
http:
http2MaxRequests: 10
maxRequestsPerConnection: 10
outlierDetection:
consecutive5xxErrors: 1
interval: 5s
baseEjectionTime: 30s
maxEjectionPercent: 100
# 배포
kubectl apply -f ch6/simple-backend-dr-outlier-locality.yaml -n istioinaction

4. Transparent timeouts and retries (실습)
네트워크 신뢰성 문제 극복 필요한 이유
- 네트워크에 분산된 구성 요소에 의존하는 시스템을 구축할 때 가장 큰 문제는 지연 시간과 실패다.
- 앞선 절에서는 이스티오에서 로드 밸런싱과 지역을 사용해 이런 문제를 완화하는 방법을 살펴봤다.
- 이 네트워크 호출이 너무 길면 어떻게 되는가?
- 또는 지연 시간이나 다른 네트워크 요인 때문에 간간이 실패한다면?
- 이스티오는 이런 문제를 해결하는 데 어떻게 도움이 될 수 있을까?
- 이스티오를 사용하면 다양한 종류의 타임아웃과 재시도를 설정해 네트워크에 내재된 신뢰성 문제를 극복할 수 있다.
4.1 Timeouts : 지연 시간
- 타임 아웃 (Timeouts) 필요한 이유
- 분산 환경에서 가장 다루기 어려운 시나리오 중 하나가 지연 시간이다.
- 처리 속도가 느려지면 리소스를 오래 들고 있을 테고, 서비스에서는 처리해야 할 작업이 적체될 수 있으며, 상황은 연쇄 장애로까지 이어질 수 있다.
- 이런 예기치 못한 시나리오를 방지하려면 커넥션이나 요청, 혹은 둘 다에서 타임아웃을 구현해야 한다.
- 중요한 점은 서비스 호출 사이의 타임아웃이 서로 상호작용하는 방법이다.
- 예를 들어 서비스 A가 서비스 B를 호출할 때 타임아웃은 1초이지만 서비스 B가 서비스 C를 호출할 때 타임이웃은 2초라면, 어떤 타임아웃이 먼저 작동하는가?
- 가장 제한적인 타임아웃이 먼저 동작하므로, 서비스 B에서 서비스 C로의 타임아웃은 발동하지 않을 것이다.
- 일반적으로 아키텍처의 가장자리(트래픽이 들어오는 곳)에 가까울수록 타임아웃이 길고 호출 그래프의 계층이 깊을수록 타임아웃이 짧은(혹은 더 제한적인)것이 합리적이다.
- 통상, 밖 → 안, backend에 위치할 수록 timeout 을 짧게 설정합니다
- 실습을 위해 환경 재설정
kubectl apply -f ch6/simple-web.yaml -n istioinaction
kubectl apply -f ch6/simple-backend.yaml -n istioinaction
kubectl delete destinationrule simple-backend-dr -n istioinaction- 호출 테스트 : simple-backend-1를 1초 delay로 응답
- 이스티오는 VirtualService 리소스로 요청별로 타임아웃을 지정할 수 있다.
- 호출 타임 아웃을 0.5로 지정 하여 타임 아웃 발생 시켜 확인 해보자
# simple-backend-1를 1초 delay로 응답하도록 배포
kubectl apply -f ch6/simple-backend-delayed.yaml -n istioinaction
# simple-backend-vs-timeout.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: simple-backend-vs
spec:
hosts:
- simple-backend
http:
- route:
- destination:
host: simple-backend
timeout: 0.5s
# 적용
kubectl apply -f ch6/simple-backend-vs-timeout.yaml -n istioinaction

4.2 Retries : 재시도
- 설정 초기화
kubectl apply -f ch6/simple-web.yaml -n istioinaction
kubectl apply -f ch6/simple-backend.yaml -n istioinaction
- Retries (재시도)
- 이스티오에서는 재시도가 기본적으로 활성화돼 있고, 두 번까지 재시도한다.
- 요청을 재시도하지 않으면, 서비스가 흔히 발새하고 예견할 수 있는 실패에 취약해져 사용자에게 좋지 않은 경험을 제공할 수 있다.
- 한편으로 무분별한 재시도는 연쇄 장애를 야기하는 등 시스템 상태를 저하시킬 수 있으므로 적절히 균형을 맞춰야 한다.
- VirtualService 리소스에서 최대 재시도를 0으로 설정
docker exec -it myk8s-control-plane bash
----------------------------------------
# Retry 옵션 끄기 : 최대 재시도 0 설정
istioctl install --set profile=default --set meshConfig.defaultHttpRetryPolicy.attempts=0
exit
- 에러 발생 시 재시도 실습
- 구성
- 주기적으로(75%) 실패하는 simple-backend 서비스 버전을 배포
- 엔드포인트 셋 중 하나(simple-backend-1)는 호출 중 75%에 HTTP 503 반환한다.
- 구성

#
cat ch6/simple-backend-periodic-failure-503.yaml
...
- name: "ERROR_TYPE"
value: "http_error"
- name: "ERROR_RATE"
value: "0.75"
- name: "ERROR_CODE"
value: "503"
...
# 배포
kubectl apply -f ch6/simple-backend-periodic-failure-503.yaml -n istioinaction
# eploy/simple-backend-1 직접 적용
kubectl exec -it deploy/simple-backend-1 -n istioinaction -- sh
---------------------------------------------------------------
export ERROR_TYPE=http_error
export ERROR_RATE=0.75
export ERROR_CODE=503
exit
---------------------------------------------------------------

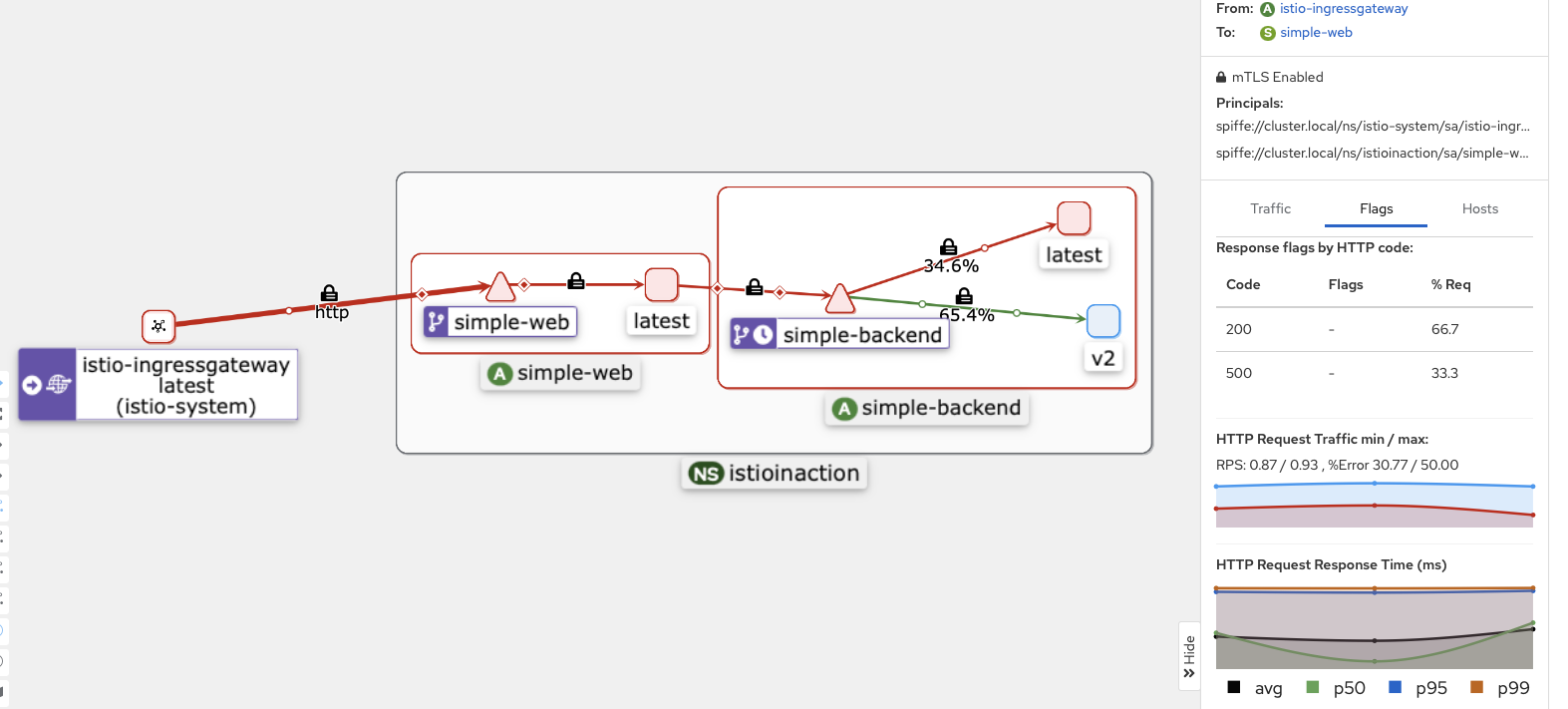
- 기본적으로, 이스티오는 호출이 실패하면 두 번 더 시도한다. 이 기본 재시도는 특정 상황에서만 적용된다.
- 일반적으로는 이들 기본 상황에서는 재시도해도 안전한다.
- 이 상황들은 네트워크 커넥션이 수립되지 않아 첫 시도에서 요청이 전송될 수 없음을 의미하기 때문이다.
- 커넥션 수립 실패 connect-failure
- 스트림 거부됨 refused-stream
- 사용 불가 gRPC 상태 코드 14
- 취소됨 gRPC 상태 코드 1
- 재시도할 수 있는 상태 코드들 이스티오에서 기본값은 HTTP
- 모든 HTTP 500 코드(커넥션 수립 실패 및 스트림 거부 포함)를 재시도하는 VirtualService 재시도 정책을 사용
#
cat ch6/simple-backend-vs-retry-500.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: simple-backend-vs
spec:
hosts:
- simple-backend
http:
- route:
- destination:
host: simple-backend
retries:
attempts: 2
retryOn: 5xx # HTTP 5xx 모두에 재시도
kubectl apply -f ch6/simple-backend-vs-retry-500.yaml -n istioinaction
- 정책 적용 후 리트라이 후 호출이 성공하는것을 확인 할수 있다.

- 사용할 수 있는 retryOn 설정은 엔보이 문서를 참조 - https://www.envoyproxy.io/docs/envoy/latest/configuration/http/http_filters/router_filter#x-envoy-retry-on
Router — envoy 1.35.0-dev-9ede1d documentation
upstream.maintenance_mode. % of requests that will result in an immediate 503 response. This overrides any routing behavior for requests that would have been destined for . This can be used for load shedding, failure injection, etc. Defaults to disabled. u
www.envoyproxy.io
타임아웃에 따른 재시도
- 각 재시도에는 자체적인 제한 시간(perTryTimeout) 이 있다.
- 이 설정에서 주의할 점은 perTryTimeout에 총 시도 횟수를 곱한 값이 전체 요청 제한 시간(이전 절에서 설명)보다 작아야 한다는 것이다.
- perTryTimeout * attempts < overall timeout
- 예를 들어, 총 제한 시간이 1초이고 시도별 제한 시간이 500ms에 3회까지 재시도하는 재시도 정책은 의도대로 동작하지 않는다.
- 재시도를 하기 전에 전체 요청 타임아웃이 발생할 것이다.
- 또 재시도 사이에는 백오프 backoff 지연이 있다는 점도 유념하자.
- perTryTimeout * attempts + backoffTime * (attempts-1) < overall timeout
- 이 백오프 시간도 전체 요청 제한 시간 계산에 포함된다.
작동 방식
- 요청이 이스티오 서비스를 서비스 프록시를 거쳐 흐를 때, 업스트림으로 전달되는 데 실패하면 요청을 ‘실패 failed’로 표시하고 VirtualService 리소스에 정의한 최대 재시도 횟수까지 재시도한다.
- 재시도 횟수가 2이면 실제로는 요청이 3회까지 전달되는데, 한 번은 원래 요청이고 두 번은 재시도다.
- 재시도 사이에 이스티오는 25ms 를 베이스로 재시도를 ‘백오프’ 한다.
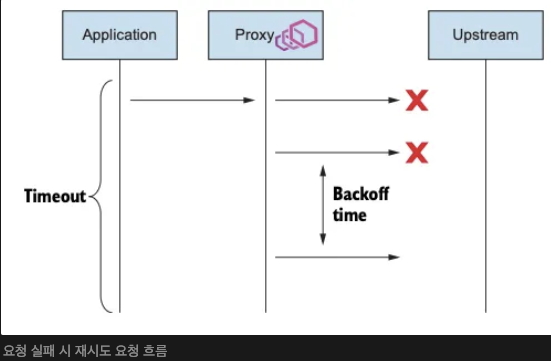
- 즉, 이스티오는 재시도에 시차를 주고자 연속적인 재시도에서 (25ms x 재시도 횟수)까지 백오프한다. (기다린다)
- 현재 재시도 베이스는 고정돼 있다.
- 그러나 다음 절에서 언급하겠지만, 이스티오가 노출하지 않는 엔보이는 API를 바꿀 수 있다.
- 상술했듯이 이스티오의 기본 재시도 횟수는 2회다.
- 시스템 내의 계층이 다르면 재시도 횟수도 다르도록 이 값을 재정의하고 싶을 수도 있다.
- 기본값과 같이 재시도 횟수를 무턱대고 설정하면, 심각한 재시도 ‘천둥 무리 thundering herd’ 문제가 발생할 수 있다.

- 서비스 체인이 5단계 깊이로 연결돼 있고 각 단계가 두 번씩 재시도할 수 있다면, 들어오는 요청 하나에 대해 최대 32회의 요청이 발생할 수 있다.
- 체인 끝부분의 리소스에 과부하가 걸린 상태에서는 이 추가적인 부하가 해당 리소스를 감당할 수 없게 만들어 쓰러뜨릴수 있다.
- 이 상황을해결하는 한 가지 방법은 아키텍처 가장자리에서는 재시도 횟수를 1회 내지 0회로 제한하고, 중간 요소는 0회로 하며, 호출 스택 깊숙한 곳에서만 재시도하게 하는 것이다. 하지만 이 방법도 잘 작동하지는 않는다.
- 또 다른 전략은 전체 재시도 횟수에 상한을 두는 것이다.
- 재시도 예산 budget 를 이용해 조절할 수 있는데, 이 기능은 아직 이스티오 API에서 노출되지 않고 있다.
- 이스티오에 이런 문제에 대한 우회로가 있기는 하지만, 이 책의 범위를 벗어나는 내용이다.
- 마지막으로 재시도는 기본적으로 자기 지역의 엔드포인트에 시도한다. retryRemoteLocalities 설정은 이 동작에 영향을 준다.
- true로 설정하면, 이스티오는 재시도가 다른 지역으로 넘어갈 수 있도록 허용한다.
- 이상값 감지가 같은 지역의 엔드포인트가 오작동하고 있음을 알아내기 전에 이 설정이 유용할 수 있다.
4.3 Advanced retries : Istio Extension API (EnvoyFilter)
- EnvoyFilter API
- 기본적으로 백오프 시간은 25ms이고, 재시도할 수 있는 상태 코드는 HTTP 503 이다
- 이스티오 확장 API를 사용해 엔보이 설정에서 이 값들을 직접 바꿀수 있다.
- 이때에는 EnvoyFilter API를 활용한다.
- EnvoyFilter API는 ‘비상용(break glass)’ 해결책이다. 일반적으로 이스티오의 API는 기저 데이트 플레인에 대한 추상화다.
- 엔보이 API는 이스티오 릴리즈마다 바뀔 수 있으므로 반드시 운영 환경에 넣은 엔보이 필터가 유효한지 확인해야 하며, 하위 호환성을 전제하면 안된다.
- 테스트
- 408 에러는 retryOn: 5xx 에 포함되지 않으므로 에러를 리턴.
- simple-backend-1 --(408)--> simple-web --(500)--> curl(외부)
# simple-backend-ef-retry-status-codes
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: simple-backend-retry-status-codes
namespace: istioinaction
spec:
workloadSelector:
labels:
app: simple-web
configPatches:
- applyTo: HTTP_ROUTE
match:
context: SIDECAR_OUTBOUND
routeConfiguration:
vhost:
name: "simple-backend.istioinaction.svc.cluster.local:80"
patch:
operation: MERGE
value:
route:
retry_policy: # 엔보이 설정에서 직접 나온다?
retry_back_off:
base_interval: 50ms # 기본 간격을 늘린다
retriable_status_codes: # 재시도할 수 있는 코드를 추가한다
- 408
- 400
# 408 에러코드를 발생
kubectl apply -f ch6/simple-backend-periodic-failure-408.yaml -n istioinaction
# 위에 코드 파드 정상 가동 후 수정
kubectl exec -it deploy/simple-backend-1 -n istioinaction -- sh
---------------------------------------------------------------
export ERROR_TYPE=http_error
export ERROR_RATE=0.75
export ERROR_CODE=408
exit
---------------------------------------------------------------
# 호출 테스트
for in in {1..10}; do time curl -s http://simple-web.istioinaction.io:30000 | jq .code; done

- 테스트-408 에러 재시도 적용
- simple-backend-1 --(408, retry 성공)--> simple-web --> curl(외부)
# simple-backend-ef-retry-status-codes.yaml
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: simple-backend-retry-status-codes
namespace: istioinaction
spec:
workloadSelector:
labels:
app: simple-web
configPatches:
- applyTo: HTTP_ROUTE
match:
context: SIDECAR_OUTBOUND
routeConfiguration:
vhost:
name: "simple-backend.istioinaction.svc.cluster.local:80"
patch:
operation: MERGE
value:
route:
retry_policy:
retry_back_off:
base_interval: 50ms
retriable_status_codes: # 재시도 하는 코드
- 408
- 400
# 적용
kubectl apply -f ch6/simple-backend-ef-retry-status-codes.yaml -n istioinaction
# simple-backend-vs-retry-on.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: simple-backend-vs
spec:
hosts:
- simple-backend
http:
- route:
- destination:
host: simple-backend
retries:
attempts: 2
retryOn: 5xx,retriable-status-codes # retryOn 항목에 retriable-status-codes 를 추가
# VirtualService에 재시도 할 대상 코드 추가
kubectl apply -f ch6/simple-backend-vs-retry-on.yaml -n istioinaction
for in in {1..10}; do time curl -s http://simple-web.istioinaction.io:30000 | jq .code; done

- 요청 헤징 (REQUEST HEDGING) 란 ?
- 재시도에 대한 마지막 이야기는 이스티오 API에서도 직접 노출하지 않는 고급 주제를 중심으로 한다.
- 요청이 임계값에 도달해 시간을 초과하면 요청 헤징을 수행하도록 선택적으로 엔보이를 설정할 수 있다.
- 요청 헤징 request hedging 이란, 요청이 타임아웃되면 다른 호스트로도 요청을 보내 원래의 타임아웃된 요청과 ‘경쟁 race’ 시키는 것을 말한다.
- 경쟁한 요청이 성공적으로 반환되면, 그 응답을 원래 다운스트림 호출자에게 보낸다.
- 만약 경쟁한 요청보다 원본 요청이 먼저 반환되면 원본 요청이 다운스트림 호출자에게 반환된다.
- 서비스에 적절한 타임아웃 및 재시도 정책을 설정하는 것은 어려운 일이며, 둘이 어떻게 연결될 수 있을지를 고려하면 더욱 그렇다.
- 타임아웃과 재시도를 잘못 설정하면 시스템 아키텍처에서 의도치 않은 동작을 증폭시켜 시스템을 과부하시키고 연쇄 장애를 일으킬 수도 있다.
- 복원력 있는 아키텍처를 구축하는 과정에서 마지막 퍼즐 조작은 재시도를 모두 건너뛰는 것이다.
- 재시도하는 대신 빠르게 실패한다.
- 부하를 더 늘리는 대신에 업스트림 시스템이 복구될 수 있도록(회복 시간 벌기) 부하를 잠시 제한할 수 있으며, 이를 위해 서킷 브레이커를 사용할 수 있다.
- 요청 헤징을 설정하려면 EnvoyFilter 리소스를 사용한다.
- 예제 소스 코드
# simple-backend-ef-retry-hedge.yaml
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: simple-backend-retry-hedge # EnvoyFilter 리소스의 이름
namespace: istioinaction # 적용할 네임스페이스
spec:
workloadSelector:
labels:
app: simple-web
configPatches:
- applyTo: VIRTUAL_HOST # Envoy 구성 중 VirtualHost에 패치 적용
match:
context: SIDECAR_OUTBOUND # 아웃바운드 트래픽
routeConfiguration:
vhost:
name: "simple-backend.istioinaction.svc.cluster.local:80" # simple-web → simple-backend
patch:
operation: MERGE
value:
hedge_policy: # 정책 설정
hedge_on_per_try_timeout: true
4.4 서킷브레이커 Circuit breaking with Istio
서킷 브레이커 소개
- 시스템 일부가 실패해도 전체 장애로 확산되지 않도록 막는 보호 장치.
- 과부하 상태의 서비스에 트래픽을 계속 보내지 않도록 차단.
- 복구를 방해하지 않고, 연쇄 실패를 방지하는 데 목적이 있다.
- 실제 전기 회로에서 차단기가 동작하는 원리와 유사하다.
- Istio에는 명시적인 CircuitBreaker 리소스는 없다.
- 방법1 - 특정 서비스의 연결 및 요청 수 제한 (Connection Pool 제어)
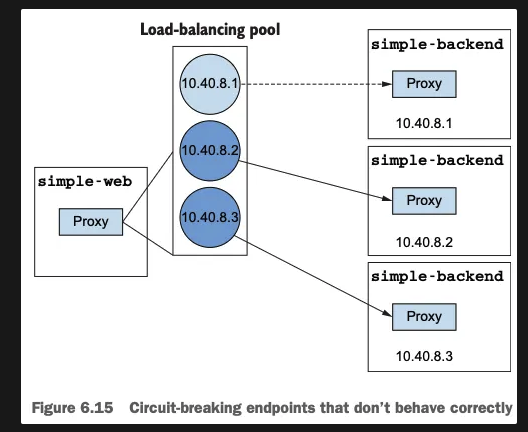
- 이스티오에서는 DestinationRule 의 connectionPool 설정을 사용해 서비스 호출 시 누적될 수 있는 커넥션 및 요청 개수를 제한 할수 있다.
- 대기 중인 요청 수 또한 제한해, 과도한 적체를 방지한다.
- 큐가 가득 차면 요청은 즉시 실패한다.
- 과부하된 서비스에 더 이상 요청을 보내지 않도록 빠르게 단락시킨다.
- 방법2 - 로드 밸런싱 풀의 엔드포인트에 상태를 관찰해 비정상 엔드포인트를 잠시 퇴출
- 장애가 반복되는 인스턴스를 자동으로 감지한다.
- 일정 기준 이상의 오류가 발생하면 인스턴스를 일시적으로 트래픽 대상에서 제외한다.
- 모든 인스턴스가 제외되면, 해당 서비스에 대한 회로는 사실상 열림(open) 상태가 된다.
- 일정 시간 이후 재검사 후 복구 가능성이 있으면 다시 포함된다.
정리
- 로드 밸런싱은 DestinationRule 리소스로 설정한다. 지원하는 알고리듬은 다음과 같다.
- ROUND_ROBIN은 요청을 엔드포인트에 차례대로(or next-in-loop) 전달하며 기본 알고리듬이다.
- RANDOM은 트래픽을 무작위 엔드포인트로 라우팅한다.
- LEAST_CONN은 진행 중인 요청이 가장 적은 엔드포인트로 트래픽을 라우팅한다.
- 이스티오는 노드의 영역 및 리전 정보를 엔드포인트 상태 정보(outlierDetection 이 설정돼 있어야 함)와 함께 활용해 트래픽을 동일 영역 내의 워크로드로 라우팅한다. (가능한 경우 그렇게 하고, 그렇지 않을 경우 다음 영역으로 넘긴다)
- DestinationRule 를 사용하면 클라이언트가 여러 지역에 가중치를 부여해 트래픽을 분배하도록 설정할 수 있다.
- 재시도와 타임아웃은 VirtualService 리소스에서 설정한다.
- EnvoyFilter 리소스를 사용하면 이스티오 API가 노출하지 않은 엔보이의 기능을 구현할 수 있다. 요청 헤징으로 이를 보여줬다.
- 서킷 브레이커는 DestinationRule 리소스에서 설정하는데, 이 기능은 트래픽을 더 전송하기 전에 업스트림 서비스가 회복할 시간을 벌어준다.
'Istio Hands-on Study [1기]' 카테고리의 다른 글
| [4주차]Observability-Observability 개념정리 및 실습 (0) | 2025.05.03 |
|---|---|
| [3주차]Traffic control,Resilience - Traffic control 개념정리 및 실습 (0) | 2025.04.26 |
| [2주차] Envoy, Isto Gateway - Istio gateways 개념 정리 및 실습 (0) | 2025.04.20 |
| [2주차] Envoy,Istio Gateway - Envoy Proxy 개념 정리 및 실습 (0) | 2025.04.18 |
| [1주차]Istio 첫걸음 - Istio 실습 환경 구성 및 체험 (0) | 2025.04.11 |
📚 목차 보기